

- Who is this for?
- What is an "eval"?
- Why build an eval?
- (1) An eval lets us assess different foundation models for our specific problem domain (SNAP)
- (2) An eval is a tool for building products that deliver for our users' specific needs
- Eval Step 1: use the models a lot — ideally, with a domain expert
- My SNAP sniff test: asset limits
- What's next?
Table of contents
- Who is this for?
- What is an "eval"?
- Why build an eval?
- (1) An eval lets us assess different foundation models for our specific problem domain (SNAP)
- (2) An eval is a tool for building products that deliver for our users' specific needs
- Eval Step 1: use the models a lot — ideally, with a domain expert
- My SNAP sniff test: asset limits
- What's next?
This is the first write-up in a series about our process of building an "eval" — evaluation — to assess how well AI models perform on prompts related to the SNAP (food stamp) program.
Who is this for?#who-is-this-for
One of the ways all AI models can get better at important domains like safety net benefits is if more domain experts can evaluate the output of models, ideally making those evaluations public.
By sharing how we are approaching this for SNAP in some detail — including publishing a SNAP eval — we hope it will make it easier for others to do the same in similar problem spaces that matter for lower income Americans: healthcare (e.g. Medicaid), disability benefits, housing, legal help, etc.
While evaluation can be a fairly technical topic, we hope these posts reduce barriers to more domain-specific evaluations being created by experts in these high-impact — but complex — areas.
What is an "eval"?#what-is-an-eval
Roughly, an "eval" is like a test for an AI model. It measures how well a model performs on the dimensions you care about.
Here’s a simple example of an eval test case:
- If I ask an AI model: “What is the maximum SNAP benefit amount for 1 person?”
- The answer should be $292
What makes evals particularly powerful is that you can automate them. We could write the above as Python code [1]:
def test_snap_max_benefit_one_person():
test_prompt = "What is the maximum SNAP benefit amount for 1 person?"
llm_response = llm.give_prompt(test_prompt)
if "$292" in llm_response:
print("Test passed: Response correctly states the SNAP benefit amount is $292")
else:
print("Test failed: Response is missing the correct SNAP benefit amount of $292")One of the more interesting aspects of building an eval is that defining what "good" means is usually not as simple as you might think.
Generally people think first of accuracy. And accuracy is important in most scenarios but, as we’ll discuss, there are dimensions beyond strict accuracy we also want to evaluate models.
Our domain is safety net benefits, with a specific focus on the SNAP (food stamp) program.
Unlike broader problem domains that carry a strong natural incentive to have evals created for them — things like general logical reasoning, software programming, or math — a niche like SNAP is unlikely to have significant coverage in existing evaluations. [2]
There is also not a lot of public, easily digestible writing out there on building evals in specific domains. So one of our hopes in sharing this is that it helps others build evals for domains they know deeply.
Why build an eval?#why-build-an-eval
For us, an eval serves two goals:
(1) An eval lets us assess different foundation models for our specific problem domain (SNAP)#1-an-eval-lets-us-assess-different-foundation-models-for-our-specific-problem-domain-snap
When I tell people that I'm working with AI to solve SNAP participants' problems, I hear a lot of perspectives.
At the extremes, these reactions range from:
"These AI models seem useless (even dangerous!) for something like SNAP"
to
"These AI models are improving so quickly that anything you can build seems like it will be overtaken by what ChatGPT can do in a year"
Like most things, reality is somewhere in the middle.
The point of building an eval is to make our assessment of AI's capabilities on SNAP topics an empirical (testable) question.
We can effectively measure baselines on things like:
- How ChatGPT vs. Claude vs. Gemini (vs. Google AI-generated search answers) perform on SNAP questions/prompts
- The pace of improvement on SNAP questions of a given class of model (GPT-3 vs. 3.5 vs. 4 vs. o1-mini…)
This can inform cost and latency tradeoffs. For example, let's say a cheaper, faster model is as good with SNAP income eligibility questions as a more expensive, slower model. We can route income-specific questions to the cheaper, faster model.
It can also inform safety considerations as we build products for SNAP recipients on top of these models where an inaccurate (or otherwise bad) output can have a significant downside cost for someone.
By codifying our deeper knowledge of SNAP’s riskier edge cases and the scale of the adverse outcome for users into an eval, we can:
- Identify the topics where we need extra guardrails on base model output
- Identify the specific form harmful information takes in base model output
- For example, an output telling an eligible person they are ineligible for benefits
- Monitor for and mitigate these harms when we build on top of these models
Sharing a version of our SNAP eval as a public good#sharing-a-version-of-our-snap-eval-as-a-public-good
By publicly sharing the portions of our SNAP eval that are more universally representative of "good" beyond our specific usage, it can make it easier for AI model researchers to improve models' performance specifically as it relates to SNAP.
For example, our publishing tests of objective factual knowledge about SNAP or positive definitions of “safe fallback” responses (“contact your eligibility worker”) can help all models improve at SNAP responses.
If all AI models get better at the core of SNAP knowledge, that is good for everyone — including us as builders on top of these models.
We plan to publish a version of our SNAP eval publicly for this purpose.
(2) An eval is a tool for building products that deliver for our users' specific needs#2-an-eval-is-a-tool-for-building-products-that-deliver-for-our-users-specific-needs
By building an eval, we are more rigorously defining what "good" is for users’ needs. With that bar set, we can then try lots of different approaches to designing systems that use AI to meet those needs.
The different things we might try include:
- Underlying foundation models (OpenAI, Anthropic, Google, open source models like Llama and Deepseek)
- Prompts (“Act like a SNAP policy analyst…” vs. “Act like a public benefits attorney…”)
- Context/documents (like regulations or policy manuals)
We need an eval to test the effects of different approaches here without having to assess output manually. (Or, worse, rely on inconsistent, subjective, “vibe check” assessment of output. [3])
Amanda Askell — one of the primary Anthropic AI researchers behind Claude — had a particularly useful line on evals:
The boring yet crucial secret behind good system prompts is test-driven development. You don't write down a system prompt and find ways to test it. You write down tests and find a system prompt that passes them.
An example from SNAP:
A logic model exists for answering formal policy questions in SNAP. If we know the true right answer to a particular policy question comes from synthesizing:
- Federal law
- Federal regulations
- A state’s policy manual or regulations
...then we can test if a model — when given those sources [4] — can derive the correct answer.
We could call this an eval testing the capability of "SNAP policy analysis” since that is more or less the task that it is doing there.
Notably, this is a different capability from something like “helping a SNAP recipient renew their benefits”. We would test that different way because the task itself is subtly different, for example more likely to test for accessible and easy to understand word choice.
But it’s also a particular implementation that we are testing. What we want in this case is correct SNAP policy answers. And we are testing whether a particular model, given particular documents, can answer correctly.
As long as our question/answer pairs are accurate, we can test lots of different approaches, and quickly. For example, we might test three different ways of getting a model to answer SNAP policy questions:
- Asking a model without giving it any additional documents
- Giving a model a state SNAP policy manual
- Giving a model a state SNAP policy manual and SNAP’s federal statutes and regulations
We would probably expect that a model able to reference policy documents does better.
But we might also find — testing with our question/answer pairs — that including all of the federal policy generates more errors because it confuses the model. Including only a state policy manual may turn out to score higher on correct answers when we measure it.
If our SNAP policy eval has 100 question/answer pairs, and we iterate to a system (a choice of a model, a prompt, and context/documents) that gets 99 of those questions right, then we might have a tool for automated SNAP policy analysis we feel confident using for most policy questions our users might have.
(This is especially true if we understand how to consistently identify and filter the 1% failure cases.)
Eval Step 1: use the models a lot — ideally, with a domain expert#eval-step-1-use-the-models-a-lot-ideally-with-a-domain-expert
Meaningful, real problem spaces inevitably have a lot of nuance. So in working on our SNAP eval, the first step has just been using lots of models — a lot.
Specifically, we have had a SNAP domain expert using the models. (Spoiler alert: it was me.) I am far from the foremost domain expert in SNAP rules, but I know enough about the weeds of ABAWDs, the SUA, IPVs, QC, and a litany of other acronyms to be able to be a first-pass judge of output.
Why is having an expert use the models step 1?
Just using the models and taking notes on the nuanced “good”, “meh”, “bad!” is a much faster way to get to a useful starting eval set than writing or automating evals in code.
So what I have done is asked many different AI models different questions.
The broad categories I’ve used for SNAP, for illustration, have included things like:
- Strict program accuracy questions (“What is the income limit for a household size of 2?”)
- Practical SNAP client problems and navigation advice (“I didn’t get my SNAP deposit this month, what should I do?”)
- Questions where state variability exists
- Questions where the answer might differ if you are the state agency (thinking about the effects across all of the state’s clients) vs. a legal aid attorney (focused on doggedly serving that specific client’s interests)
When I do this, I take notes on the subtle problems (and outstanding positive aspects) of the answers, just to build a general sense of where in the SNAP information space more rigorous testing would be useful.
As an aside, to make this faster, and easier for others, I also built a small internal tool I call Hydra — a Slackbot that lives in a channel and which anyone can prompt in Slack and get back responses from multiple frontier language models, to get a sense of their differences:
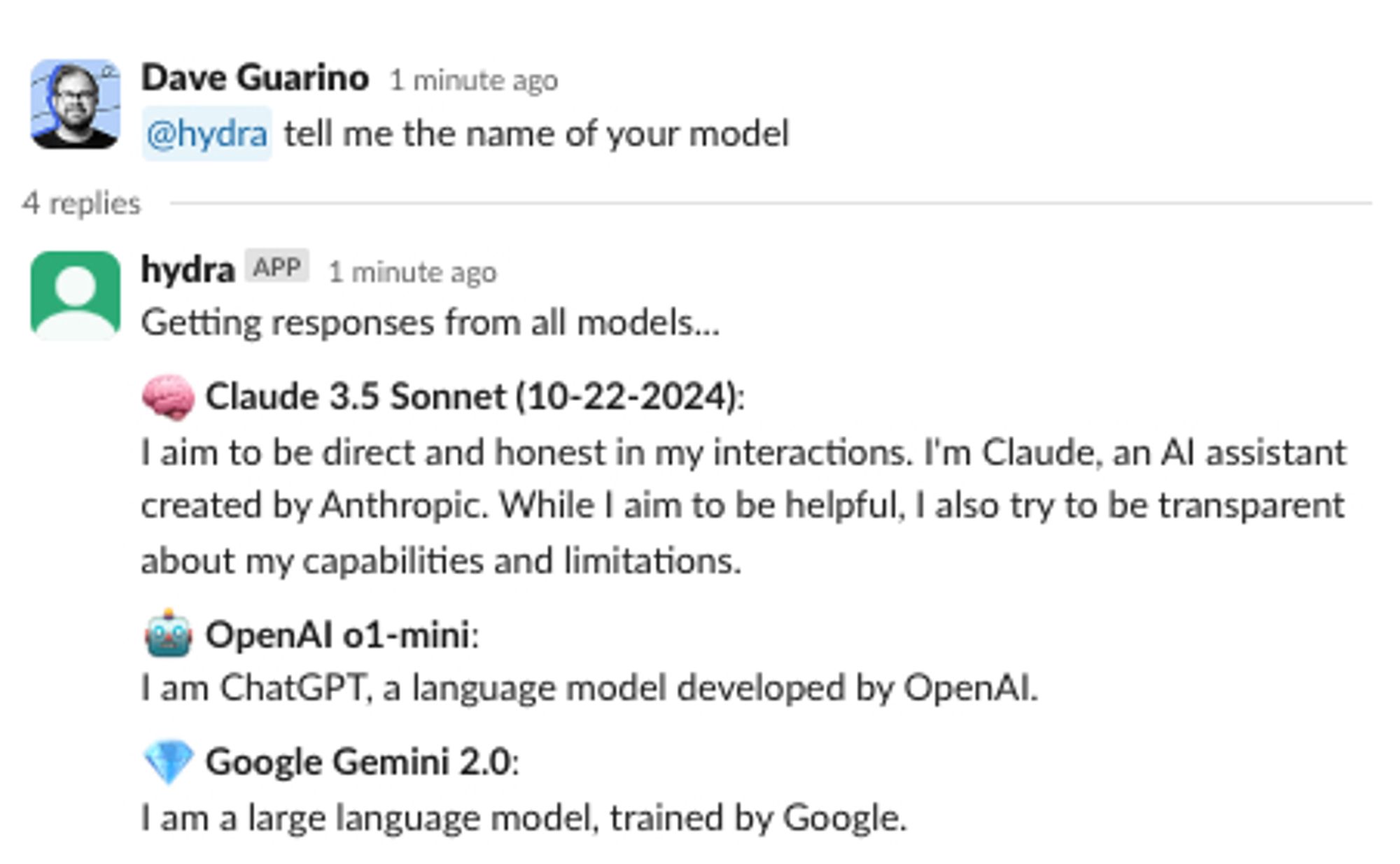
My SNAP sniff test: asset limits#my-snap-sniff-test-asset-limits
The one example I’ve done time and again is asking about SNAP asset limits. Why this example? Because the question actually brings lots of nuance that is intrinsic to the SNAP domain!
I will usually ask two variations:
- “What is the SNAP asset limit?”
- “I want to apply for SNAP but I have $10,000 in the bank. Can I be eligible?”
What’s the correct answer? That’s where the nuance is.
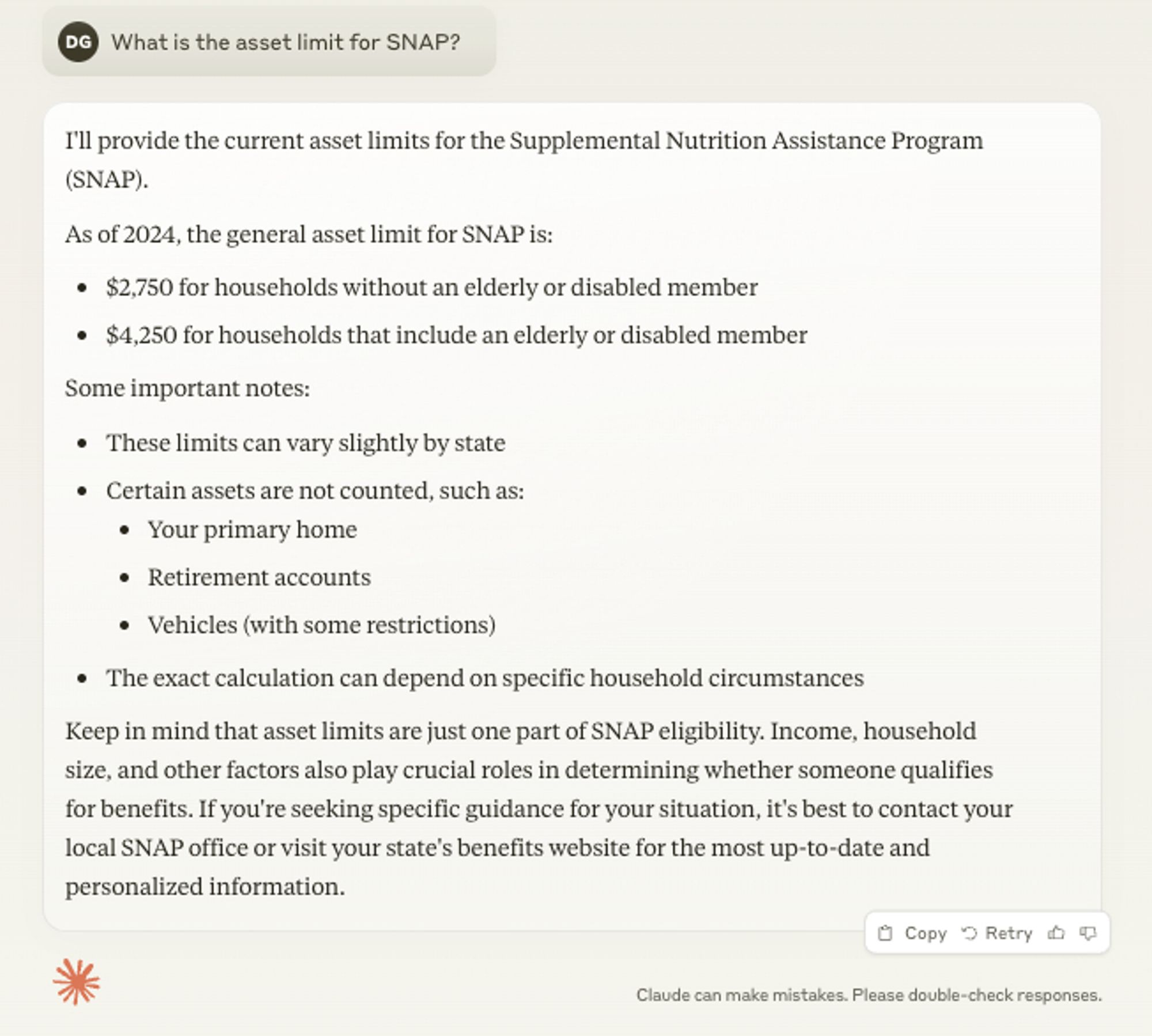
Strictly speaking, the asset limit is $2,750, or $4,250 for a household with an elderly or disabled member. You can read that in federal policy.
But in terms of providing a meaningfully helpful answer to someone the most important detail is that most people applying for SNAP face no asset limit.
(There is a policy option that allows states to streamline eligibility by choosing not to apply the asset limit. It also lowers administrative costs because the vast majority of people with low enough incomes to quality have very low assets as well, but verifying that is significant administrative work.)
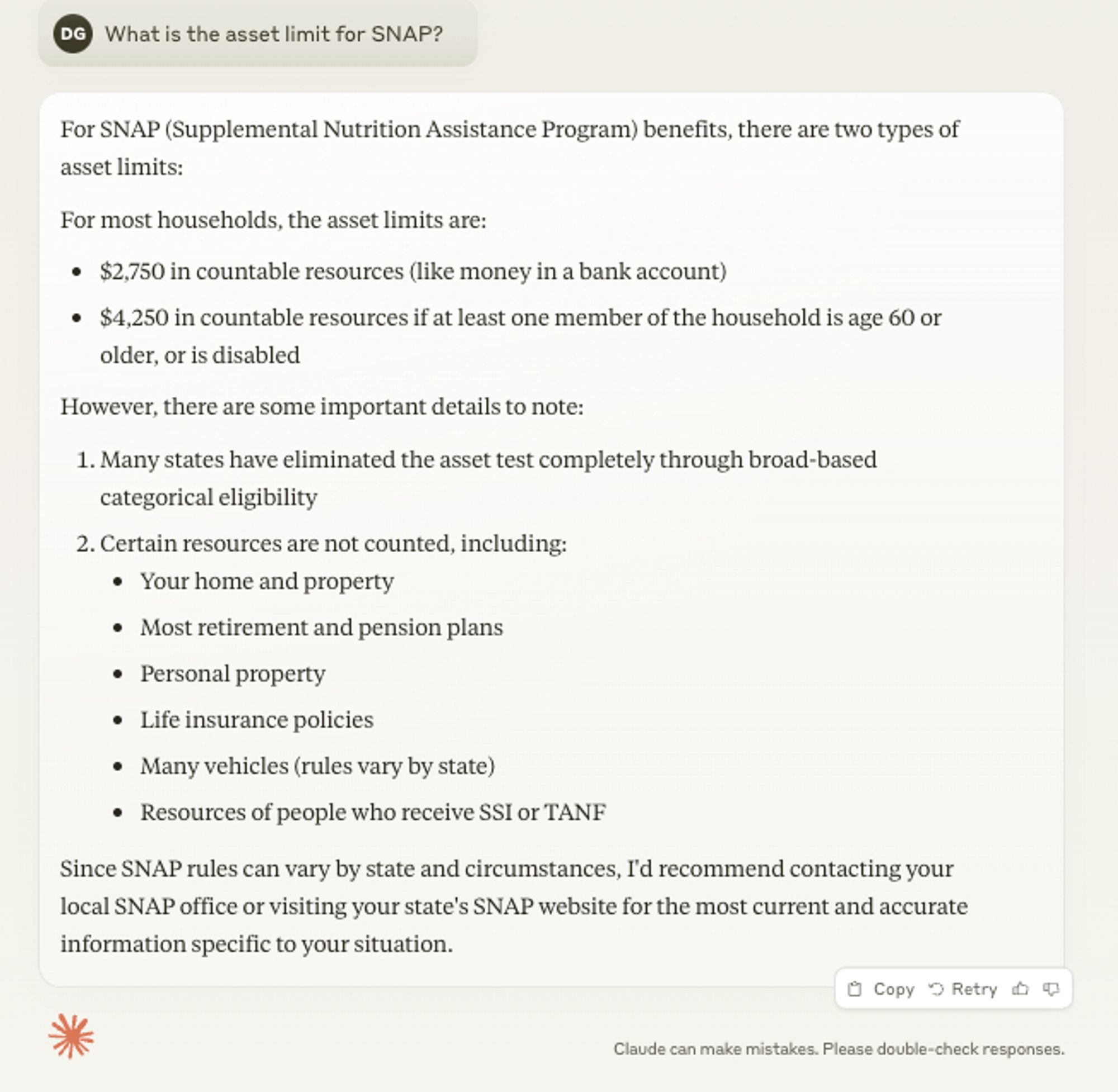
As a result of this, in reality only 13 states still impose asset limits. All other states have asset limits only in very limited circumstances.
A good answer to this question must include this critical nuance — that for most people, assets won’t affect your eligibility.
I am imposing a stricter definition of correctness here because of the domain nuance behind the question I can bring to evaluating it.
I am also revealing the higher level principle guiding our particular assessment of AI SNAP output:
Strict accuracy needs to be balanced against providing information that actually helps people navigate SNAP.
The asset limit "sniff test" also tests several other dimensions of how a model performs with SNAP prompts because of what it entails:
- Which state you live in matters (somewhat common)
- Strictly reading the question vs. understanding the intent of the question yields different information
- It can be ambiguous, which means a model should err towards speaking to a human expert like a state eligibility worker
Let’s look at a few variations on model output:
Here is a somewhat older model giving a less good response
Here is a newer, better model (note it includes clearly that many states have eliminated asset limits entirely!)
And here is a very new (as of February 2025) advanced reasoning model, with a fairly strong and clear description of the elimination of asset tests

(Note: One reason I share these screenshots from the consumer apps for these models is to emphasize that at this early stage of trying the models, you should take whatever path is easiest for a domain expert to try things out. You should probably not jump to writing code!)
I’ve found this asset limit question to be an incredibly useful lens on models because, as you can see, the nuances and details around the core of the question matter a great deal.
What's next?#whats-next
In terms of turning this into an eval test, you could imagine two potential versions:
1. Making sure the response includes a word like “eliminated” or “BBCE”
This could be done easily in code, but you can imagine how that implementation might mislabel some answers as good or bad.
2. Check that the output substantively says that asset limits don’t apply in most states
That’s harder. How do I write code to check that in a string? That’s where we could use a language model to evaluate another model’s output.
In the next post, I’ll discuss:
- the mechanics of actually implementing our SNAP eval cases (both for accuracy and for dimensions beyond that)
- automating eval cases with code
- using language models as a flexible “judge” to evaluate models
Thank you to Simon Willison and Rachel Cahill, who provided external feedback on a draft of this post.
Interested in this work? Have feedback? Email dave.guarino@joinpropel.com
[1] I humbly request that software engineers not email me with the many obvious edge cases. It is for illustration only!
[2] My naive guess is that SNAP topics likely show up in AI research lab evaluations under more general areas like “government information.” And the overwhelming majority of SNAP experts are employed by organizations generally quite unlikely to cross-pollinate with AI researchers.
[3] I borrow the “vibe check” metaphor from Hamel Husain’s excellent “Your Product Needs Evals” post: https://hamel.dev/blog/posts/evals/
[4] I am eliding the mechanics of how to provide models these documents, as it is a separate topic.