Building a SNAP LLM eval: Part 2 - testing and automation
Our editorial promise
All of our Propel editorial content meets our high bar for accuracy, timeliness, trust, and relevance. Our pages are edited and fact-checked to make sure we meet our mission of giving you information you can rely on.
Learn more about our editorial standards.
(This is part 2 in a series. See part 1 where we discussed what an eval is and why building one is valuable, as well as part 3 where we walked through actually testing nuanced SNAP capabilities in AI models.)
In part 1, we looked at the basics of what an eval is, why to build one, and started to get into the how for our specific problem space: the food stamp (SNAP) program.
The first step was having someone with a strong SNAP understanding go and use the models a lot. By poking with different inputs, we built some sense of what good and bad outputs looked like concretely.
Our two different eval goals: benchmarking and product development#our-two-different-eval-goals-benchmarking-and-product-development
Before continuing with the “how” of building our SNAP eval, it’s important to note that we actually have two distinct goals, and so in practice we are building two different evals with a common foundation — but they will diverge at a point.
Goal 1: Benchmarking current base models on SNAP topics#goal-1-benchmarking-current-base-models-on-snap-topics
Our first goal is simply to assess how well the most advanced models do on a variety of questions, prompts, and tests related to the SNAP domain.
The eval test cases we write for this goal will generally be more objective, factual, and grounded in consensus (rather than being highly opinionated.)
For example, we might be more tolerant of a general purpose model refusing to answer a particular question where an incorrect answer would have significant adverse consequences.
Benchmarking is useful for us for choosing what to build on top of, but it also more directly provides public value: if we can identify 10 concrete problems in ChatGPT or Google AI Search Result SNAP responses, it can help those very highly-used models improve. But for benchmarking, we want to err on the side of more objectivity and consensus.
Goal 2: Using an eval to guide product development#goal-2-using-an-eval-to-guide-product-development
Other portions of our eval will be more specific and opinionated based on what we are trying to build, and how we plan to deploy it.
For example, in our case, we might weight a refusal to answer much more negatively than a general benchmark because we seek to build the most helpful SNAP-specific assistant for clients. (And because we know for many SNAP clients a refusal may then lead to waiting on hold for an hour to speak to someone at their SNAP agency.)
By “opinionated” I mean that this evaluation will be specific to the goal of our product. While SNAP has lots of common knowledge, you can imagine the evaluations will be different for:
- “AI SNAP Policy Helper for Agency Eligibility Staff”, vs.
- “AI SNAP Client Advocate for Limited English Proficiency Applicants”
We discussed Step 1 in our first post, so now we can move to the next step in our process.
Step 2: testing factual knowledge#step-2-testing-factual-knowledge
The next step for us in building out our SNAP eval is writing tests of factual knowledge.
Starting with factual tests is useful for us because:
- If a model gets important facts wrong, it is likely to perform poorly when given more complex tasks that rely on those facts (for example, assessing whether an income denial is correct or should be appealed requires a knowledge of the program’s income limits)
- SNAP, as a domain, has many objective facts — where an answer is unambiguously right or wrong — that we can test for
- Factual tests are easier to write and generally easier to automate
Some examples of some purely factual SNAP questions related to eligibility:
- What is the maximum SNAP benefit amount for a household of 1?
- Can a full time college student be eligible for SNAP?
- Can you receive SNAP if you get SSI?
- Can you receive SNAP if you’re unemployed?
- Can undocumented immigrants receive SNAP?
- What is the maximum income a single person can make and receive SNAP?
It’s important to note that we do want to be somewhat goal-directed here. We’re not testing models’ knowledge of facts just to test them.
Rather, if we know there is necessary prerequisite knowledge to successfully accomplish a higher level goal — like helping someone determine if they’re likely eligible, and so should go through the work of applying for SNAP — then it’s worth testing that.
By testing the above, for example, we see that many models actually provide an outdated maximum income limit for SNAP. (To their credit, when asked, they generally do specify it is specifically for fiscal year 2024.)
Those limits change once every October based on a cost of living adjustment, and most models (tested in February of 2025) provide information from the prior fiscal year. This makes sense due to the knowledge cutoff — the fact that models take a while to train, and therefore base models often don’t have the most recent information.
This is less of a “gotcha” than a useful signal as we build systems on top of these models.
When we identify gaps in factual knowledge in base models, it means two things:
- For benchmarking, we’ve identified problems
- For product development, we’ve identified an opportunity to bring in external sources of knowledge for our models to use in generating responses
For example, for building a product ourselves, we can still use a model that has outdated income limit information as the basis for an eligibility advice tool — we would just give it the most recent income limits as another input to use before it generates a response.
Including external knowledge is a separate topic from our eval, but this is where techniques like retrieval augmented generation (RAG) or using models with large context windows become relevant.
With a number of factual knowledge tests in hand, we arrive at our next constraint: it takes a lot of time to run these tests manually!
Step 3: automating eval tests#step-3-automating-eval-tests
Our next step is automating our eval tests. One of the benefits of starting with factual eval tests first is that automating them is fairly easy. The logic will look something like this:
- Objective: Test whether a model can provide an accurate max monthly SNAP benefit amount
- Input prompt: “What is the maximum benefit I can get as a single person from SNAP?”
- Criteria to evaluate the answer: it should include “$292”
You can go about automating this test in a number of different ways. You can start by having an LLM generate a simple eval harness to run them with custom code. OpenAI has an “evals” framework. And a number of open source and commercial tools exist.
We are using an open source tool called Promptfoo.
One of the top reasons I used Promptfoo for this is that I want creating evals to become more accessible to experts in topics that aren’t software engineers.
And one of the very best features of Promptfoo is that you can run evals directly from a Google Sheet.
So an expert can write in a document like this:
And then we can run the eval with a simple command and get this output:

To talk through this, what happened here is that:
- We asked each of 3 different AI models (OpenAI’s GPT-4o-mini, Anthropic’s Claude 3.5 Sonnet, and Google’s Gemini 2.0 Flash Experimental)...
- The same question: What is the maximum benefit I can get as a single person from SNAP?
- And then we checked to see if they included the correct answer of $292
With many of our factual SNAP test cases, we can make them easily automated by using approaches like:
- Checking that they include a specific word or phrase
- Making the model return either YES or NO only
- Giving it a multiple choice answer
So now, instead of having to put in lots of time-intensive manual work, we can simply write tests in our spreadsheet, hit run, and compare performance across models.
Here’s a set of more miscellaneous factual questions:

And now we can compare the output of different models across all of these.
In this specific (non-representative!) test set, we see Claude succeeding about 73% of the cases, while the other two models pass only about 45% of the cases.

We can also look at all of the output, iterate on how we define the test of “good”, and also come up with other evaluation criteria by looking at the longer form responses we receive for each question from each model.
Step 4: automating more complicated evaluation by using models as “judges” of answers#step-4-automating-more-complicated-evaluation-by-using-models-as-judges-of-answers
It’s a bit obvious that many ways in which we might decide a response is “good” in reality are more nuanced than “it contains this word or number.”
Luckily, what we can do there is use the AI models themselves to evaluate answers on more complicated criteria.
For example, one common theme I hear from SNAP experts is that any tool that is SNAP client-facing should really emphasize plain, accessible language.
We can in fact build this into our evaluation!

By running this test, we use AI to determine whether the output was in accessible language:
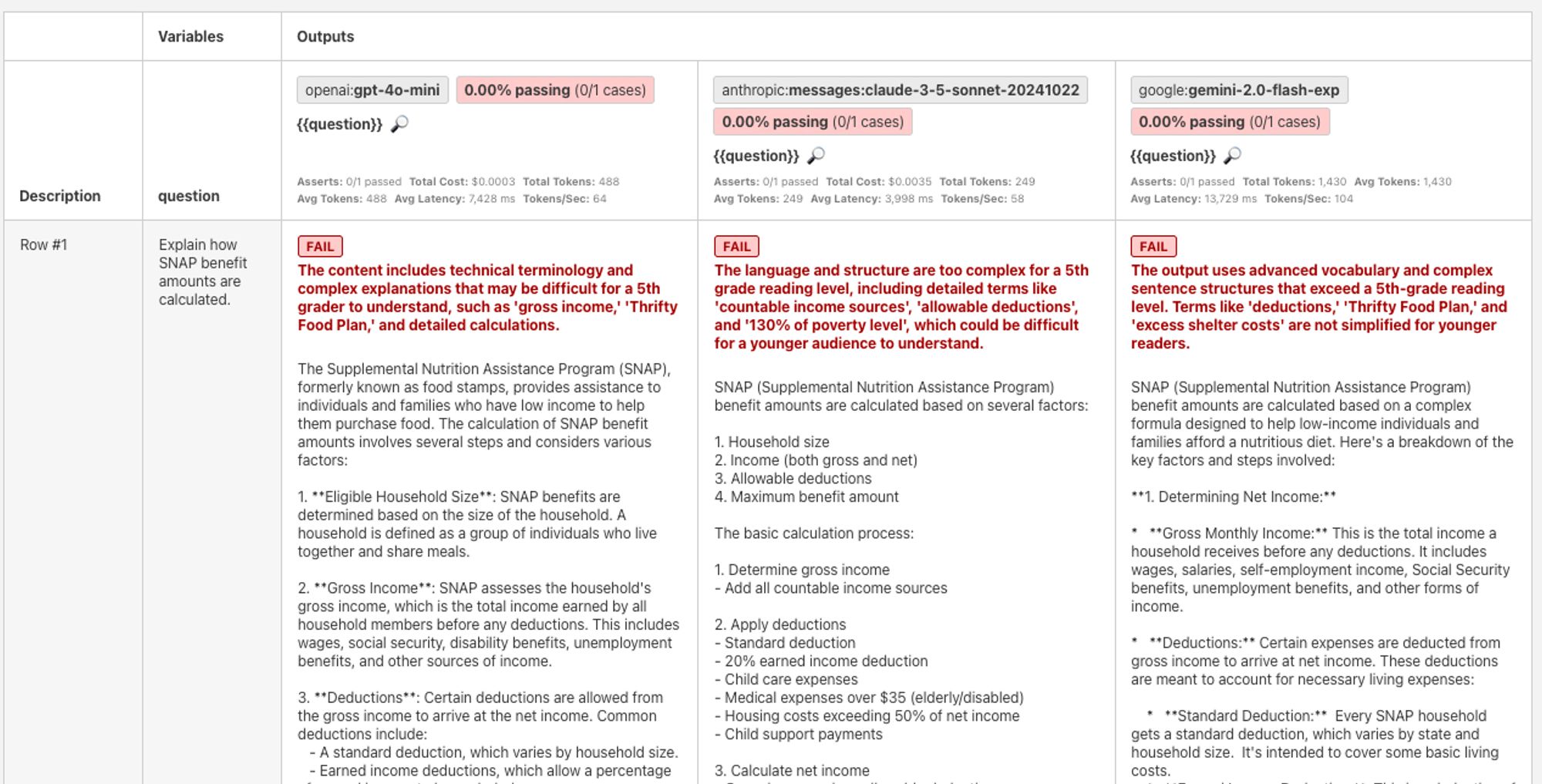
To pull out one assessment:
“The language and structure are too complex for a 5th grade reading level, including detailed terms like 'countable income sources', 'allowable deductions', and '130% of poverty level', which could be difficult for a younger audience to understand.”
The ability to use AI models to themselves evaluate AI model output is highly valuable. It means that instead of having to rely on human inspection for the harder, messier criteria, we can automate much more of it — and as a result, perform much wider testing.
In the next part of this series, we’ll walk through using this approach to test some of the nuanced, messy, and specific sorts of criteria that are important for SNAP specifically — and show benchmark data about how the most advanced models do on these dimensions.